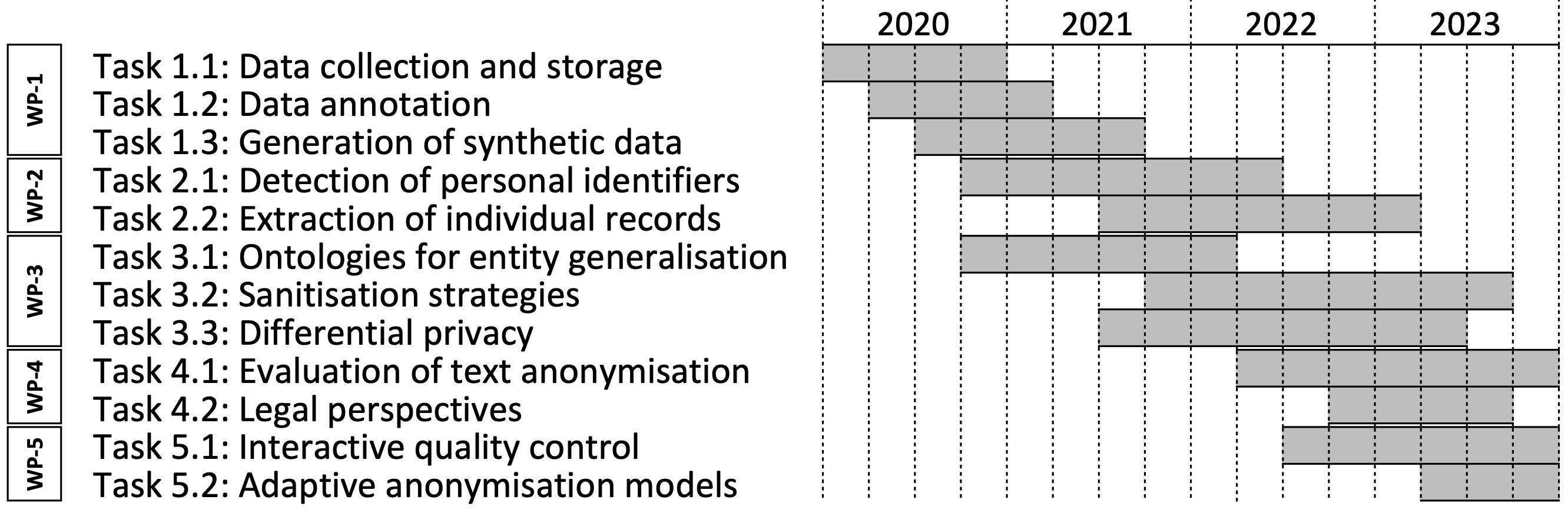
Summary of the project objectives:
The project sets out to develop new computational models and processing techniques to automatically anonymise unstructured data containing personal information, with a specific focus on text documents.
The project's key idea is to combine approaches from natural language processing and data privacy to design a new generation of text anonymisation techniques that simultaneously:
- Take advantage of state-of-the-art natural language processing techniques (based on deep neural architectures) to derive fine-grained records of the individuals referred to in a given document
- Connect these individual records to principled measures of disclosure risk and data utility, with the goal of modifying text documents in a way that prevents the disclosure of personal information while preserving as closely as possible the internal coherence and semantic content of the documents.
The project will also design dedicated evaluation methods to assess the empirical performance of text anonymisation mechanisms, and examine how these metrics are to be interpreted from a legal perspective, in particular with respect to how privacy risk assessments should be conducted on large amounts of text data. Finally, the project will investigate how these technological solutions can be integrated into organisational processes - in particular how quality control can be performed in direct interaction with text anonymisation tools, and how the level and type of anonymisation can be parametrised to meet the specific needs of the data owner.
To achieve these objectives, the project brings together a consortium of researchers with expertise in machine learning, natural language processing, computational privacy, statistical modelling, health informatics and IT law. In addition, external partners from the public and private sector (covering the fields of insurance, welfare, healthcare and legal publishing) will also contribute to the research objectives with their data and domain knowledge.